Batch poster recovery
This section covers how the batch poster recovers state after a crash, restart, or bad start—including DB restore from a batch-poster checkpoint, storage backends, revert and halt recovery, Redis failover, nonce sync, and reorg handling.
The batch poster is mostly stateless—its checkpoint lives on L1
The batch poster does not primarily checkpoint its position in its own database. On every posting attempt it reconstructs where to resume from authoritative sources: the SequencerInbox contract on L1 plus the local inbox tracker DB. Its own data-poster DB holds only the in-flight transaction queue (transactions sent but not yet confirmed), for replace-by-fee (RBF). This is why recovery is robust: lose the data-poster DB and the poster still knows exactly where to resume.
Recovery state machine flow
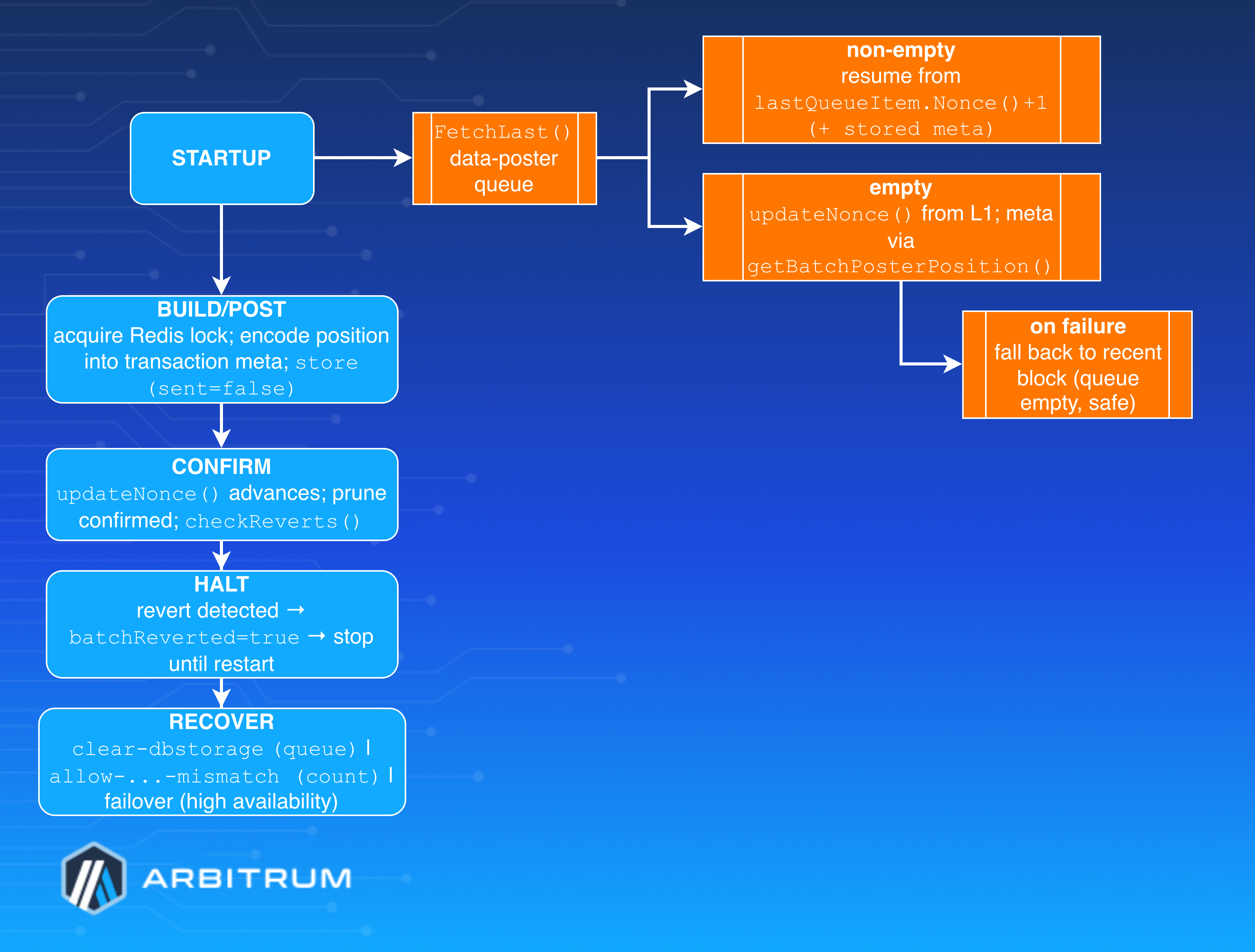
Recovery state machine flow
The position "checkpoint"
This is wired as the data poster's MetadataRetriever. So the "checkpoint" (batchPosterPosition: message count, delayed count, next sequence number) is RLP-encoded into each transaction's metadata, but the source of truth is L1 + the inbox tracker, not a snapshot.
func (b *BatchPoster) getBatchPosterPosition(ctx context.Context, blockNum *big.Int) ([]byte, error) {
bigInboxBatchCount, err := b.seqInbox.BatchCount(...) // <-- read from L1 contract
...
prevBatchMeta, err = b.batchMetaFetcher.GetBatchMetadata(inboxBatchCount - 1) // <-- inbox tracker DB
return rlp.EncodeToBytes(batchPosterPosition{
MessageCount: prevBatchMeta.MessageCount,
DelayedMessageCount: prevBatchMeta.DelayedMessageCount,
NextSeqNum: inboxBatchCount,
})
}
How resume actually works on restart
FetchLast()the data-poster queue. If non-empty (transactions survived restart), resume fromlastQueueItem.Nonce()+1with its stored metadata—continues exactly where it left off, RBF-ing pending transactions.- If empty, call
updateNonceto sync nonce from L1, then fetch position metadata viagetBatchPosterPosition. IfupdateNoncefails and the queue isn't persistent (or can't wait for finality), it falls back to a recent block (the"failed to update nonce with queue empty; falling back to using a recent block"warning)—safe precisely because nothing is queued.
In short: queue intact → resume in-flight; queue gone → rebuild cleanly from L1.
Storage backends and what survives a restart
| Backend | File | Persists? | Recovery behavior |
|---|---|---|---|
| dbstorage | dataposter/dbstorage/storage.go | Yes (consensus DB, BatchPosterPrefix table) | Queue rehydrated from keyed entries; FetchContents/FetchLast reload on startup |
| redisstorage | dataposter/redis/redisstorage.go | Yes (shared) | Sorted-set keyed by nonce; HMAC-signed entries; enables failover |
| slice | dataposter/slice/slicestorage.go | No (in-memory) | Lost on restart; used when parent chain is Arbitrum (no mempool) |
| noop | dataposter/noop/storage.go | No | Stores nothing; post-and-forget |
Notably, when the parent chain itself is an Arbitrum chain, the data poster forces no-op storage—there's no L1 mempool to RBF into, so there's nothing to persist or recover.
Recovery mechanism 1: dangerous.clear-dbstorage
When the persisted queue gets into a bad state, set --node.batch-poster.data-poster.dangerous.clear-dbstorage. At construction, with DB storage active, it calls PruneAll before starting:
func (s *Storage) PruneAll(ctx context.Context) error {
idx, err := s.lastItemIdx(ctx) // dbstorage/storage.go:94
...
return s.Prune(ctx, until+1) // delete every entry through the last
}
Prune iterates and batch-deletes all keys below the bound and rewrites the count. After clearing, the empty-queue path above rebuilds nonce and position from L1. Use once, then unset—it discards in-flight transaction tracking, so clearing while transactions are genuinely pending risks nonce conflicts or double-posting. It's a no-op unless use-db-storage is the active backend.
Recovery mechanism 2: revert → halt, and force-inclusion recovery
Halt on revert.
pollForReverts watches L1; checkReverts finds a failed receipt from the poster's sender and returns shouldHalt := ~UsingNoOpStorage(). On a confirmed revert it sets b.batchReverted.Store(true) and MaybePostSequencerBatch then refuses to post: "batch was reverted, not posting any more batches". This is deliberate—a revert means something is wrong; the poster stops rather than burn funds. Recovery requires operator investigation and a restart (which clears the in-memory batchReverted flag).
Force-inclusion mismatch
dangerous.allow-posting-first-batch-when-sequencer-message-count-mismatch handles the case
where the poster's DB message count drifts from the chain's sequencerReportedSubMessageCount. The scenario: poster down >24h, someone force-includes a delayed message via the parent contract (which doesn't bump sequencerReportedSubMessageCount), so on restart the inbox reader's count diverges. The fix:
prevMessageCount := batchPosition.MessageCount
if b.config().Dangerous.AllowPostingFirstBatchWhenSequencerMessageCountMismatch && !b.postedFirstBatch {
...
prevMessageCount = 0 // contract skips the prevMessageCount equality check when it's 0
}
Setting prevMessageCount = 0 tells the SequencerInbox to skip the equality check, so the
first post goes through and re-aligns the on-chain count. It applies only to the first
batch after startup (!b.postedFirstBatch) — once posted, the mismatch resolves itself.
Recovery mechanism 3: Redis failover (high availability)
Multiple posters coordinate via redislock, default Enable: true, LockoutDuration: 1m, RefreshDuration: 10s:
- Primary holds the lock: the loop checks
CouldAcquireLockand logs"Not posting batches right now because another batch poster has the lock or this node is behind"on backups. - If the primary crashes, the lock expires after
LockoutDuration; a backup withbackground-lockacquires it. - The backup recovers shared state from Redis queue storage, which is HMAC-signed so a tampered queue is rejected. Nonce continuity comes from
updateNonceagainst L1.
So failover state-sharing rides on persistent, signed Redis storage plus L1-derived nonce and position.
Recovery mechanism 4: nonce/sync on restart
updateNonce queries the finalized (or latest) L1 nonce; when it advances past s.Nonce it logs "Data poster transactions confirmed" and prunes confirmed txs from the queue (Prune(ctx, nonce-1)). On a failed fetch with a prior nonce it's non-fatal ("Failed to get current nonce" warning). wait-for-l1-finality (default true) governs whether it tracks finalized vs latest — trading confirmation latency for reorg safety.
Reorg handling
- Parent-chain reorg, revert polling: if the chain went backward (
nextRevertCheckBlock > blockNum) it resets to re-check; the >100-block gap warning fast-forwards and skips. - Mempool nonce-gap avoidance: before sending a transaction of a different type than its predecessor (or whose predecessor isn't yet reorg-resistant), it checks
NonceRbfSoftConfsdeep and, if the nonce exceeds the reorg-resistant count, leaves the transaction queued—"DataPoster is avoiding creating a mempool nonce gap"—rather than risk a gap a reorg would expose. l1-block-bound(safe/finalized/latest/ignore) andreorg-resistance-margin(default 10m) keep batches from referencing L1 blocks that could reorg out (seeposting-cadence-and-lifecycle.mdandconfig-flags.md).
Where state physically lives
The data-poster DB is a table within the consensus DB: rawdb.NewTable(consensusDB, storage.BatchPosterPrefix). The inbox tracker independently persists SequencerBatchCountKey/DelayedMessageCountKey (initialized to 0 if absent). A full DB restore therefore restores both the in-flight queue and the inbox-tracker counts—but even a wiped data-poster table self-heals from L1.
Operator recovery cheat-sheet
- Corrupt or stuck queue → restart with
data-poster.dangerous.clear-dbstorage(once), then remove it. - Batch reverted or poster halted → investigate the revert, then restart to clear
batchReverted. - Message-count mismatch after force-inclusion or long downtime → restart with
dangerous.allow-posting-first-batch-when-sequencer-message-count-mismatch(first batch only). - Primary died, HA configured → automatic failover after
lockout-duration; backup resumes from signed Redis state + L1 nonce. - Lost data-poster DB entirely → no manual action needed; position rebuilds from L1 + inbox tracker, queue starts empty.